Intro To Azure Data Factory (ADF) you need to learn right now!
What is ADF? / ETL / Main Component of ADF / Advantages/Limitations of ADF


Introduction
Hi There, I'm Aditya Narayan Nayak. A few months ago, I got a requirement for making a CI/CD pipeline in the Azure Data factory. I was too excited about Azure DevOps Pipeline because it's pretty simple and exhausting also, but at that time I didn't know what the heck is Azure Data Factory.
Then I started googling "What is ADF". This is Where I got introduced to the word "ETL" it took me around 20 min to visualize how it works. Now from there makes a CI/CD pipeline. I have gone through a beautiful journey which I'm going to share, so please stay tuned with me 😉.
The Problem with Big Data!

The problem with big data, Relational data, non-relational data, and other storage systems. This data doesn't have the proper context for meaning or providing any meaningful insights because of its vast data, so the analyst or data scientist can't use this data and make any decisions on this raw data. Big data requires a service that can work the street and personalized processes to refine vast stores of raw data into actionable business
Example: -

Just imagine a gaming company that collects petabytes of games logs that are produced by the game in the cloud this company wants to analyze these logs to gain insights into customers' preferences or demographics, for example, and usage behavior, it also wants to identify upsell and cross-sell opportunities developed for example new features, drive business grows and to provide a better experience to its customer. After all that they want to gather all this data to monitor and get insights, so how they can do this let's see.
What is ETL?
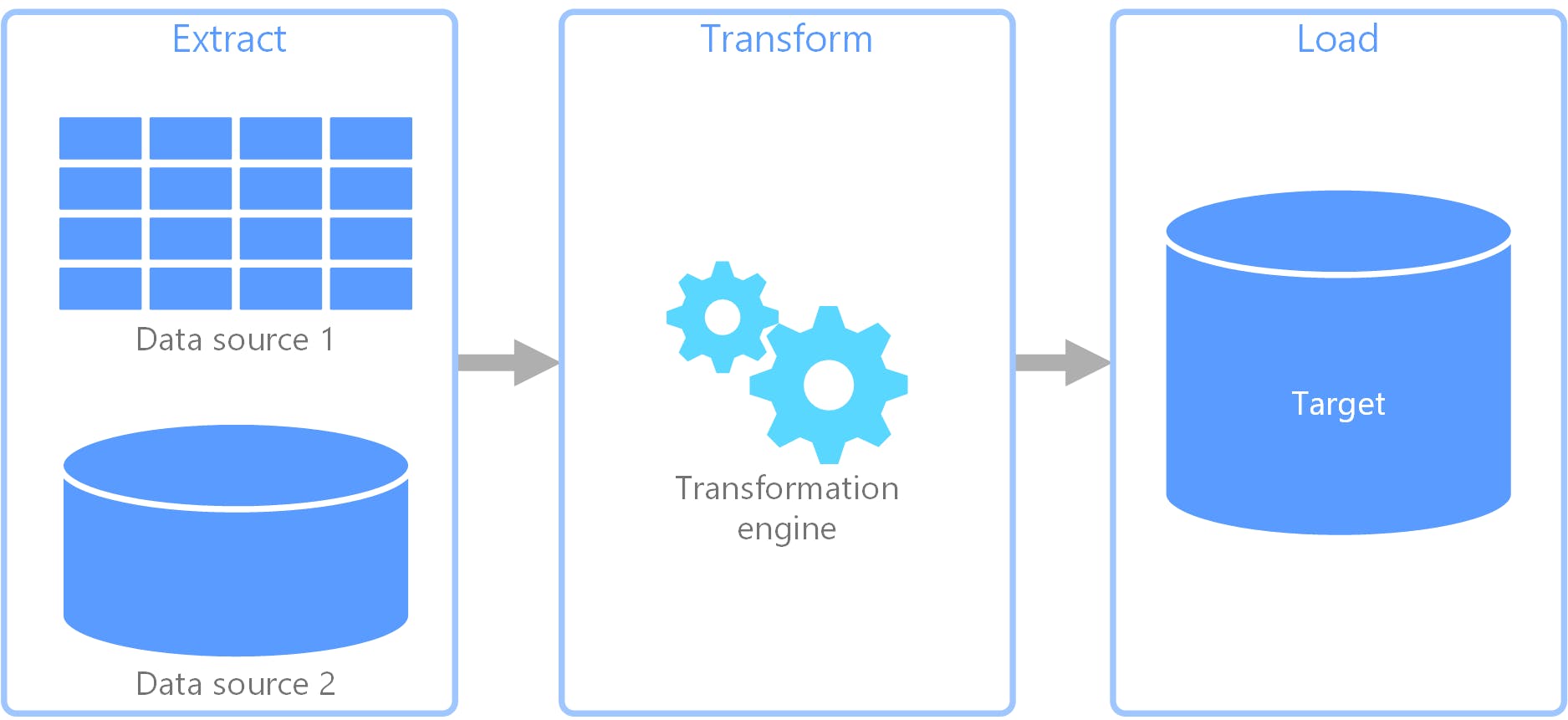
Extract, transform, and load (ETL) is a data pipeline. That Works similarly to the CPU, which takes input And processes it and at least it will give output as destination storage.
In ADF ETL is a data pipeline used to collect data from various sources. It then transforms the data according to business rules, and it loads the data into a destination data store
What is Azure Data Factory?
Azure Data Factory is a fully managed Serverless cloud-managed solution that builds for big data solutions with hybrid extract transform load (ETL)
So, it's a cloud-based ETL platform and data integration service that allows for the creation of data-driven workflows for orchestrating data movement and transformation data at scale. Also, Because of the cloud-based solutions, the scalability is high.

Using ADF We can create and schedule data-driven workflows that can eat data from disparate data stores we can build complex ETL processes that transform data visually with data flows or by using compute services like Azure HD Insights, Hadoop, Azure Data bricks, and Azure SQL data
Additionally, we can publish our transformation data to a data store such as a SQL data warehouse for the business intelligence applications to consume ultimately through a data factory raw data can be organized into meaningful data stores and data lakes for better business Decisions
How Does it Work?
Usually, there is a data source and a Destination
The Data source could be Azure SQL/AWS s3 bucket or any data source type variety of data source
We have a destination that could be an Azure Storage account /SQL/SQL data warehouse/Data warehouse it has Lots of option
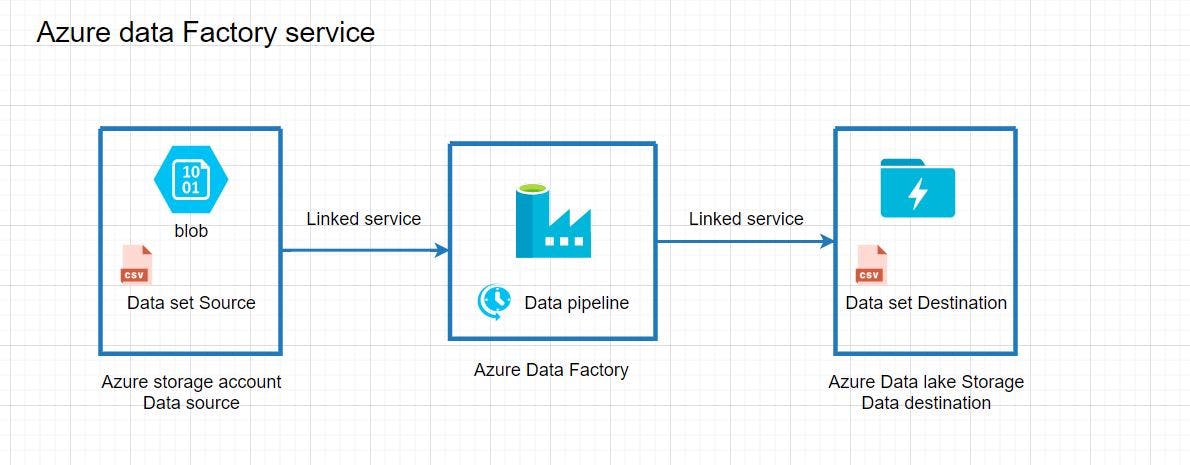
Now we have to move data from Source to destination, in order to do this job We have to use Azure Data factory.
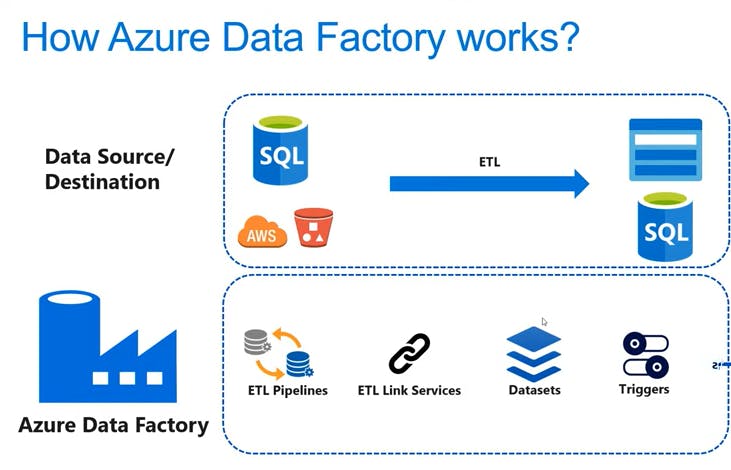
ETL pipeline will identify what is the source and what is a destination
These pipeline use link services which contain information about the connection between the source and the destination
Then there will be a Data set that includes the connection data sets to Source and Destination.
Last, Triggers are used to schedule a Data Pipeline runs without any interventions.
What are the Main Components of Azure Data factory?
Pipeline:-
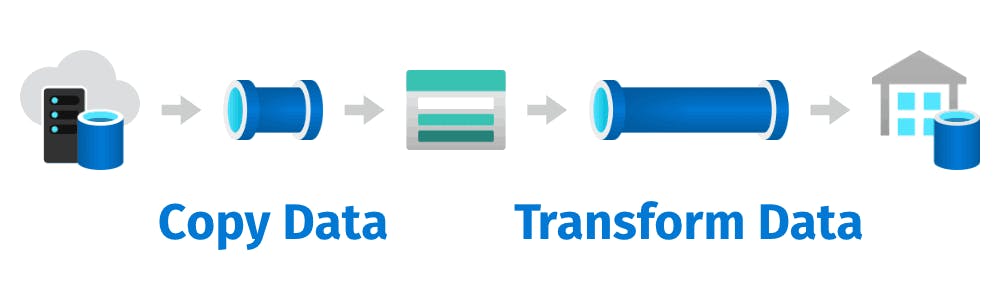
In simple terms, a pipeline in Azure Data Factory is a set of actions that move and transform data from a source to a destination
Imagine in the factory a raw product is processed and move to a different place for process, Assembly at the end it will come as a finished product.
Similarly, a pipeline in ADF is a sequence of activities that perform data-related tasks, such as copying data from one location to another, transforming data, and performing various data manipulation operations.
DataSet:-
The dataset describes the properties of the Data Source and Data destination.
In simple terms, It specifies where the data is coming from and where it's going, how the data is structured, and how it should be processed
Linked Service:-
Linked Service is a configuration that defines the connection information to an external data source.
Think of it as a "link" between your Data Factory and a data storage or processing system, such as a database, file system, or cloud storage.
Mapping:-
Mapping Data Flows allows you to visually design and execute data transformations on large volumes of data.
In simple terms, it's a way to transform data from one format to another, such as converting CSV files to JSON or merging data from multiple sources into a single table.

Triggers:-
Triggers allow you to specify when a pipeline or a set of pipelines should be run automatically, without any manual intervention.
There are several types of triggers such as
Schedule Trigger:- Runs pipelines on schedule, such as daily or weekly
Event Trigger:- Runs pipelines based on an event, such as when a file is added to a folder or when a new message is received in a queue
Integration Runtime:-

Integration Runtimes in Azure Data Factory are the compute instances that are used to run and manage data workflows.
There are 3 types of integration Runtime in ADF:-
Azure Integration Runtime:- These are the default integration runtime provided by ADF.
Self-hosted Integration Runtime:- These are the integration runtime provided by us like integration runtime installed VM and on-premise server.
Azure-SSIS Integration Runtime:- AZ-SSIS (IR) is made on top of the Azure Integration Runtime to Run SQL Server Integration Services (SSIS) packages
What are the Advantages and Limitations of Azure Data Factory?

Advantages:-
No-code data pipelines - Without writing a single line of code, you can set up Azure Data Factory to acquire and integrate data from the most popular data sources, including file systems, cloud storage services, and databases
SSIS migration is simple - One of the biggest advantages of Azure Data Factory for businesses is how easily SSIS data pipelines can be extracted and moved to Azure Data Factory.
Integrated monitoring and alerting- Built-in monitoring visualization is available in Azure Data Factory. With the help of these inbuilt visibility options, you can easily monitor the progress of data integration processes.
Limitations:-
Consumption-based pricing has several advantages, but it may have a higher total cost of ownership in the long run than on-premises solutions.
For complex JSON when it comes to mapping nested attributes it's not easy to flatten out
Data Factory V1 does not have a good implementation experience as compared to V2
Conclusion
In this blog, we have explored what Azure Data Factory is, how it works, and what are some of its advantages and disadvantages. We have seen that Azure Data Factory is a powerful cloud-based service that enables data integration and orchestration across various sources and destinations. It offers a graphical interface for designing and monitoring pipelines, as well as a rich set of built-in activities and connectors.

Thank you So much For giving your valuable time for Reading this blog. If you like this blog give.
Follow me on hash node/Twitter/LinkedIn/Instagram for Azure Contents.